vrrp 구성 (Active-Standby or Active-Active) 시 UTM 장비 failover 시 sync 패킷 전송 중 panic 발생하는 문제가 있었다.
외부 고객사에서 발생한 문제라 내부 재현은 불가능하여 코드 분석 레벨에서 session 동기화 과정에서의 버그 발생 지점을 분석해보았다.
vrrp 구성 (Active-Standby or Active-Active) 시 UTM 장비 failover 시 sync 패킷 전송 중 panic 발생하는 문제가 있었다.
외부 고객사에서 발생한 문제라 내부 재현은 불가능하여 코드 분석 레벨에서 session 동기화 과정에서의 버그 발생 지점을 분석해보았다.
iptables 정책 적용 후에도 기존 세션이 남아 hit count를 업데이트 하고 있는 이슈를 맡게된 계기로
상태를 가진 세션 기반 방화벽처리에 대해 조사해보았다.
1. iptables rule sequence 수정 후에도 수정 전 정책으로 패킷 카운팅 되고 있음을 확인
2. 해당 호스트는 PC ↔ eth0 (UTM) ↔ eth1 (UTM) ↔ 인터넷 의 구조로 PC 에 대한 라우터 역할을 수행하고 있었음
3. reply 패킷의 경우 원래 PREROUTING hook을 안타지만 인터넷 → PC 에 대한 reply 패킷은 PREROUTING → FORWARD → POSTROUTING hook을 타고 처리됨
4. rule 적용은 PREROUTING hook의 mangle table에서 orig 패킷만 적용됨
5. reply 패킷은 conntrack rule 에 의해 기존 conntrack table의 세션 마크를 재사용하도록 되어있음
5. rule 수정 후 reply 패킷이 PREROUTING hook을 탈 경우 수정한 rule 이 반영되지 않고 conntrack table의 세션 마크에 의해 수정전의 룰이 반영됨
다음 그림과 같이 모델링된 production 구성에서 정책 수정시 수정 전 정책으로 패킷 카운팅되는 문제가 발생했다.
.png)
먼저 정책 2개를 추가하고 icmp ping을 흘려보았다.
*mangle
-A PREROUTING -m fivetuple --msrc 100.1.1.0/24 -j MARK --set-mark 0x321002
-A PREROUTING -m fivetuple --msrc 100.1.1.0/24 -j MARK --set-mark 0x1e100130, 50 룰 icmp traffic
iptables -t mangle -L -vn
Chain PREROUTING (policy ACCEPT 8108 packets, 579K bytes)
pkts bytes target prot opt in out source destination
193 21954 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 connmark match !0x0/0xffffffffffffffff CONNMARK restore
49 11461 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 reply
144 10493 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 connmark match 0x1/0x1
165 11026 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK set 0xfde80001
105 7261 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK set 0x321002
105 7261 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK set 0x1e1001
105 7261 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK or 0xa000000000000
0 0 MARK icmp -- * * 0.0.0.0/0 0.0.0.0/0 icmp type 13 MARK set 0x0
165 11026 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 CONNMARK save mask 0xffffffffffffffff30 → 20, 50 → 30 룰 수정 후 traffic test (이 경우 우선순위가 낮은 30번 룰이 카운팅 되는 문제였다.)
iptables -t mangle -L -vn
Chain PREROUTING (policy ACCEPT 15377 packets, 1077K bytes)
pkts bytes target prot opt in out source destination
228 16008 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 connmark match !0x0/0xffffffffffffffff CONNMARK restore
16 1261 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 reply
212 14747 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 connmark match 0x1/0x1
77 4192 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK set 0xfde80001
5 323 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK set 0x1e1002
5 323 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK set 0x141001
5 323 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 --msrc 192.168.1.0/24 MARK or 0xa000000000000
0 0 MARK icmp -- * * 0.0.0.0/0 0.0.0.0/0 icmp type 13 MARK set 0x0
77 4192 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 CONNMARK save mask 0xffffffffffffffff룰을 수정하지 않아도 iptables 의 후순위 룰의 패킷수는 카운팅이 되었다.
mangle tables 에서는 access/drop/reject 에 대한 마킹만하고 실제 정책을 확인하여 패킷에 대한 drop 판단을 하는 곳은 filter tables이다. 그렇기 때문에 iptables의 결과는 문제가 없었다.
UTM 장비에서 packet counting 로직은 filter tables 에서 last time 을 업데이트하면 패킷 카운팅 결과를 출력하는 로직으로 구성되어있었다.
1. 룰이 netfilter hook을 타고 이동하면서 정책이 적용되고 카운팅되는 로직 분석
2. 상태를 가진 세션의 경우 룰 변경 시 어떻게 상태를 유지하며 룰이 반영되는지
iptables 의 경우 순차적으로 매칭하여 룰 개수 증가 시 성능이 급격하게 저하되는데 사내 UTM 장비의 경우 iptables-tng 코드를 패치하여 tuple 기반으로 hash table을 활용한 classify 기능을 추가하여 룰 개수가 많아져도 일정한 CPS를 유지하도록 하도록 개발되어있었다.
관련 개발 사항과 룰 적용 시 패킷이 netfilter hook에서 어떻게 처리되는지 분석해보았다.
개발 내역
다음과 같이 ssh 접속시 패스워드 변경 기능을 추가한다.

먼저 SSH의 packet은 다음과 같이 구성되어 있다.
| Packet Length | Padding Length | Payload | Random Padding | Message Authentication Code (MAC) |
// ssh packet 형식
uint32 packet_length // payload + padding 길이 (4바이트)
byte padding_length // padding 길이 (1바이트)
byte[n1] payload // 메시지 데이터 (메시지 타입 + 메시지 본문)
byte[n2] random padding // 암호화 블록 크기 맞추기용 랜덤 패딩
[MAC] optional, if MAC is enabled // 메시지 인증 코드 (무결성 확인용, 선택적)
// 키 교환 패킷 예시 (SSH_MSG_KEXINIT)
packet_length: 0x000001fc
padding_length: 0x0c
payload: (message type 20) + kex algorithms, hostkey algorithms, etc.
padding: 12 bytes of random data
MAC: (only if enabled, e.g. hmac-sha2-256)Wireshark로 캡처한 SSH 패킷이다.
HMAC은 세 가지 필드로 구성되어있다. 패딩, 페이로드, 랜덤 패딩의 내용은 암호화된 패킷 필드에 있다.
.png)
.png)
(https://www.iana.org/assignments/ssh-parameters/ssh-parameters.xhtml)
| 메세지 타입 번호 | 메세지 이름 | 설명 |
| 1 | SSH_MSG_DISCONNECT | 연결 종료 |
| 2 | SSH_MSG_IGNORE | 무시 가능한 패킷 |
| 20 | SSH_MSG_KEXINIT | 키 교환 초기화 |
| 21 | SSH_MSG_NEWKEYS | 새로운 키 적용 |
| 30~49 | 키 교환 관련 메시지들 | ECDH 등 포함 |
| 50 | SSH_MSG_USERAUTH_REQUEST | 사용자 인증 요청 |
| 52 | SSH_MSG_USERAUTH_SUCCESS | 인증 성공 |
| 90 | SSH_MSG_CHANNEL_OPEN | 채널 열기 |
| 94 | SSH_MSG_CHANNEL_DATA | 터미널 데이터 송신 |
SSH 는 다음과 같은 세가지 레이어로 구성되어있다.
.png)
.png)
1. SSH 연결이 설정되면, 클라이언트와 서버는 키 교환을 통해 안전한 통신 채널을 설정한다.
2. 클라이언트는 서버에 사용자 인증을 수행한다.
3. 인증이 성공하면 클라이언트는 SSH_MSG_CHANNEL_OPEN 메시지를 보내 새로운 채널을 열 수 있다.
byte SSH_MSG_CHANNEL_OPEN
string "session"
uint32 sender channel
uint32 initial window size
uint32 maximum packet size4. 채널이 생성된 후 클라이언트가 SSH_MSG_CHANNEL_OPEN 메시지를 보내고, 서버가 이 요청을 수락하면, 클라이언트는 이제 해당 채널을 통해 데이터를 주고받을 수 있다.
5. 클라이언트는 SSH_MSG_CHANNEL_REQUEST 메시지를 통해 특정 작업을 요청할 수 있다. (pty-req, shell)
Dropbear는 SSH 프로토콜의 경량 구현이다. SSH 서버는 Dropbear 기반으로 MatrixPKI(matrixssl에 포함된 버전으로) 또는 OpenSSL 호환 API로 구현하는 호환 레이어(cryptowrapper*)로 구성되어있다.
dropbear 커스텀 코드 분석
비밀 번호 인증 절차는 다음과 같은 절차로 이루어진다.
1. 클라이언트 -> 서버 (SSH_MSG_USERAUTH_REQUEST)
2. 서버 -> 클라이언트 - SSH_MSG_USERAUTH_INFO_REQUEST
3. 클라이언트 -> 서버 - SSH_MSG_USERAUTH_INFO_RESPONSE - password
byte SSH_MSG_USERAUTH_REQUEST
string user name
string service name
string "password"
boolean FALSE
string plaintext password in ISO-10646 UTF-8 encoding [RFC3629]4. 서버 -> 클라이언트 - SSH_MSG_USERAUTH_SUCCESS
비밀 번호 인증 로직을 기반으로 비밀번호 만료 로직을 다음과 같이 설계했다.
.png)
1. 클라이언트 -> 서버 - SSH_MSG_USERAUTH_REQUEST
2. 서버 -> 클라이언트 비밀 번호 요청 - SSH_MSG_USERAUTH_INFO_REQUEST
3. 클라이언트 -> 서버 - SSH_MSG_USERAUTH_INFO_RESPONSE
4. 서버 -> 클라이언트 비밀번호 만료, 새 비밀번호 요청 - SSH_MSG_USERAUTH_INFO_REQUEST
byte SSH_MSG_USERAUTH_PASSWD_CHANGEREQ
string prompt in ISO-10646 UTF-8 encoding [RFC3629]
string language tag [RFC3066]
byte SSH_MSG_USERAUTH_REQUEST
string user name
string service name
string "password"
boolean TRUE
string plaintext old password in ISO-10646 UTF-8 encoding [RFC3629]
string plaintext new password in ISO-10646 UTF-8 encoding [RFC3629]5. 클라이언트 -> 서버 새 비밀번호를 두 번 입력 - SSH_MSG_USERAUTH_INFO_RESPONSE
6. 서버 -> 클라이언트 비밀번호 변경 성공 알림 - SSH_MSG_USERAUTH_INFO_REQUEST -> SSH_MSG_USERAUTH_SUCCESS
0. _dropbear_log, _dropbear_exit 등 callback 함수 치환
#define _dropbear_log(...) zlog_info(__VA_ARGS__)
#define _dropbear_exit(...) custom_exit_handler(__VA_ARGS__)1. svr_session 구조를 통째로 쓰지 않고 필요한 부분만 직접 실행
2. chaninitialise() 할 때 우리가 만든 핸들러로 교체
svr_chantypes[CHAN_SESSION].inithandler = my_vty_chansess_init;
3. ses.packettypes에 custom handler 등록
static const packettype svr_packettypes[] = {
{SSH_MSG_USERAUTH_REQUEST, recv_msg_userauth_request}, /* server */4. service_loop() 직접 호출
5. session 수동 생성
int sv[2];
socketpair(AF_UNIX, SOCK_STREAM, 0, sv);6. 인증 처리
7. channel 과 세션 연결
커널 기반 가상 머신(KVM)은 물리적 Linux 시스템에 설치하여 가상 머신을 생성할 수 있는 소프트웨어 기능이다. 가상 머신은 물리적 시스템과 CPU 사이클, 네트워크 대역폭 및 메모리와 같은 리소스를 공유한다. KVM은 Linux에서 가상 머신에 대한 네이티브 지원을 제공하는 Linux 운영 체제 구성 요소이다.
Manufacturer: eSlim Korea
Operating System: CentOS Linux 7 (Core)
processor-version: Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz
Kernel: Linux 3.10.0-1160.el7.x86_64$ lscpu | grep -i "virtualization\|svm"
Virtualization: VT-x
$ egrep '(vmx|svm)' /proc/cpuinfo | wc -l
48BIOS 진입 -> IntelRCSetup -> Processor Configuraion -> VMX Enabled
BIOS 진입 -> IntelRCSetup -> Intel VT for Directed I/O (VT-d) Enabled$ hostnamectl
Static hostname: localhost.localdomain
Transient hostname: localhost
Icon name: computer-server
Chassis: server
Machine ID:
Boot ID:
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64-- 그래픽 환경(GNOME Desktop) 추가
$ yum groupinstall "X Window System" "GNOME Desktop"
-- 그래픽 환경 default 설정
$ systemctl set-default graphical.target
-- 그래픽 환경 지원 모드 확인
$ systemctl get-default
graphical.target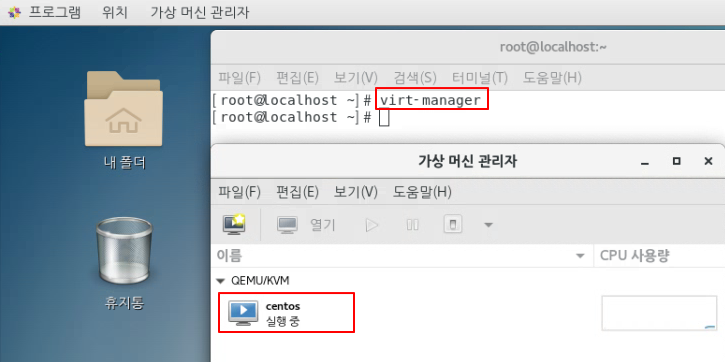
$ yum install virt-install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install virt-manager -y-- 1. br0 생성
$ vi /etc/sysconfig/network-scripts/ifcfg-br0
TYPE=Bridge
BOOTPROTO=none
NAME=br0
DEVICE=br0
ONBOOT=yes
IPADDR=10.0.10.235
PREFIX=24
GATEWAY=10.0.10.1
DNS1=8.8.8.8
-- 2. eth0 를 br0 bridge에 연결 : ifcfg-eth0 마지막줄에 BRIDGE 설정 추가 하고 ip는 삭제
$ vi /etc/sysconfig/network-scripts/ifcfg-eth0
BRIDGE=br0
-- 3. 반영
$ service network restart
-- 4. 확인
$ brctl show
bridge name bridge id STP enabled interfaces
br0 8000.2c600c8be5d0 no eth0
nerdctl10 8000.da23e99d353b no vethbe5ee88a
nerdctl11 8000.b2cd54f28bbd no vethb7164a2d
virbr0 8000.525400737e4b yes virbr0-nic
vnet-- 방화벽 활성화
$ systemctl start firewalld
-- guest vm 이 점유할 포트에 대한 방화벽 규칙 추가
$ firewall-cmd --zone=public --add-port=7000-9000/tcp --permanent
-- 반영
$ firewall-cmd --reload
-- 반영확인
$ firewall-cmd --list-all-- 외부 -> 호스트:{목적지 포트} 로 들어오는 연결 허용
$ iptables -I INPUT -p tcp -s 0.0.0.0/0 --dport {목적지 포트} -j ACCEPT
</pre>
* libvirt 데몬 실행
<pre>
$ systemctl enable --now libvirtd
$ systemctl enable --now virtlogdqemu-img create -f [format] [저장할 이미지파일] [용량]
ex: qemu-img create -f qcow2 centos.qcow2 100G$ virt-install \
--name centos \
--ram 8192 \
--vcpus=4\
--check-cpu \
--os-type=linux \
--cdrom CentOS-7-x86_64-Minimal-2009.iso \
--disk path=centos.qcow2,device=disk,format=qcow2,bus=virtio \
--network bridge=virbr0 \
--hvm \
--vnc \
--vncport=8196 \
--vnclisten=0.0.0.0 \
--boot hd \
--noautoconsole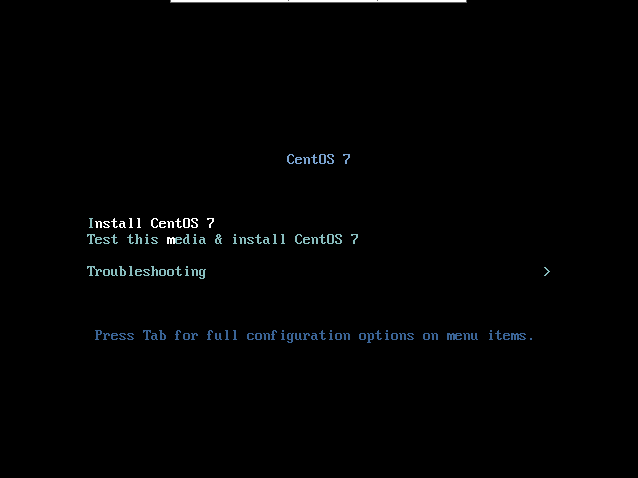
$ vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="... console=tty0 console=ttyS0,115200n8 net.ifnames=0 biosdevname=0"
$ grub2-mkconfig -o /boot/grub2/grub.cfg
-- kvm host server에서 console로 접속
$ virsh console <KVM 이미지>
$ cd /etc/sysconfig/network-scripts/
$ mv ifcfg-ens32 ifcfg-eth0
$ vi ifcfg-eth0
BOOTPROTO=dhcp
DEVICE=eth0
ONBOOT=yes
$ service network restart
-- kvm host server에서 할당받은 dhcp ip 확인
$ virsh net-dhcp-leases default
-- 호스트 -> 게스트 VM:22 포트로의 TCP 연결 허용
$ iptables -I FORWARD -m tcp -p tcp --dport 22 -j ACCEPT
-- DNAT 처리 (Port forward: {목적지 포트} --> 22)
$ iptables -t nat -A PREROUTING -p TCP --dport {목적지 포트} -j DNAT --to {게스트 VM IP}:22
-- 접속 확인
$ ssh root@10.0.10.235:{목적지 포트}TCP/IP stack을 개발하는 것은 어려운 작업일 수 있으나 핵심사양은 비교적 간결하다.
중요한 부분은 TCP header 파싱, 상태 머신, 혼잡 제어, 재전송 시간 초과 계산이다.
가장 일반적인 Layer2와 Layer3 프로토콜인 Ethernet과 IP는 각각 TCP의 복잡성에 비하면 간단하다.
리눅스 TAP 장치를 이용하여 리눅스 커널에서 저수준 네트워크 트래픽을 가로챌 수 있다.
TUN/TAP 장치는 일반적으로 User Space application이 각각 L3/L2 트래픽을 조작하는데 사용된다. 인기있는 예로는 패킷을 다른 패킷의 페이로드 내부에 래핑하는 터널링이 있다.
TUN/TAP 장치의 장점은 User Space 프로그램에서 설정이 쉽고 OpenVPN 과 같은 다수의 프로그램에서 이미 사용되고 있다는 점이다.
Layer2 부터 네트워크 스택을 구축하기 위해선 TAP 장치가 필요하다. 다음과 같이 인스턴스화 할 수 있다.
/*
* Kernel Documentation/networking/tuntap.txt에서 발췌
*/
int tun_alloc(char *dev)
{
struct ifreq ifr;
int fd, err;
if( (fd = open("/dev/net/tap", O_RDWR)) < 0 ) {
print_error("Cannot open TUN/TAP dev");
exit(1);
}
CLEAR(ifr);
/* Flags: IFF_TUN - TUN 장치 (이더넷 헤더 없음)
* IFF_TAP - TAP 장치
*
* IFF_NO_PI - 패킷 정보 제공 안 함
*/
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
if( *dev ) {
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ){
print_error("ERR: Could not ioctl tun: %s\n", strerror(errno));
close(fd);
return err;
}
strcpy(dev, ifr.ifr_name);
return fd;
}이 후 반환된 파일 디스크립터 fd 를 사용하여 가상 장치의 이더넷 버퍼로 데이터를 읽고 쓸 수 있다.
여기서 IFF_NO_PI가 중요하다. 이 플래그를 넣지 않으면 이더넷 프레임에 불필요한 패킷 정보가 앞에 붙게 된다.
drivers/net/tun.c 파일을 보면 IFF_NO_PI 플래그가 설정되지 않은 경우, 패킷 정보 구조체를 프레임에 추가하는 것을 알 수 있다.
if (!(tun->flags & IFF_NO_PI)) {
if (len < sizeof(pi))
return -EINVAL;
len -= sizeof(pi);
if (!copy_from_iter_full(&pi, sizeof(pi), from))
return -EFAULT;
}
다양한 이더넷 표준은 IEEE 802.3 작업 그룹에 의해 유지된다.
Ethernet Frame Header 는 다음과 같고 C 구조체로 선언할 수 있다. (https://www.ietf.org/rfc/rfc1042.txt)
Header Format
Header
...--------+--------+--------+
MAC Header | 802.{3/4/5} MAC
...--------+--------+--------+
+--------+--------+--------+
| DSAP=K1| SSAP=K1| Control| 802.2 LLC
+--------+--------+--------+
+--------+--------+---------+--------+--------+
|Protocol Id or Org Code =K2| EtherType | 802.2 SNAP
+--------+--------+---------+--------+--------+#include <linux/if_ether.h>
struct eth_hdr
{
unsigned char dmac[6];
unsigned char smac[6];
uint16_t ethertype;
unsigned char payload[];
} __attribute__((packed));dmac과 smac은 각각 dst, src mac address를 가리킨다.
overloaded 된 ethertype은 2 octet field로 그 값에 따라 payload length 또는 protocol type으로 사용될 수 있다.
ethertype field 다음에는 ethernet frame 의 여러가지 tag가 올 수 있다. 여기서 tag는 frame의 vlan 또는 qos 유형을 설명하는데 사용될 수 있다. (여기선 생략)
payload field는 ethernet frame의 payload에 대한 pointer를 포함한다. 이 경우 ARP 또는 IPv4 패킷을 포함할 것이다. payload의 길이가 최소 48 byte(tag 제외) 보다 작으면 요구사항을 충족하기 위해 pad byte가 payload 끝에 추가된다.
또한 ethernet type과 해당 16진수 값 간의 매핑을 제공하는 if_ether.h 리눅스 헤더(이더넷 프로토콜에 관련된 상수와 구조체가 정의됨)를 포함한다.
#define ETH_P_IP 0x0800 // IPv4 프로토콜
#define ETH_P_ARP 0x0806 // ARP 프로토콜
#define ETH_P_IPV6 0x86DD // IPv6 프로토콜마지막으로 ethernet frame 형식은 frame check sequence field 를 마지막에 포함하며 이는 순환 중복 검사(CRC)를 사용하여 프레임의 무결성을 검사하는데 사용한다. (여기선 생략)
구조체 선언에서 packed 속성은 구현 세부 사항이다. 이는 GNU C 컴파일러에게 데이터 정렬을 위한 패딩 바이트로 구조체 메모리 레이아웃을 최적화하지 않도록 지시(구조체의 필드들 사이에 패딩 바이트를 추가하지 말라고 지시)하는데 사용된다.
packed 속성은 구조체의 필드들이 특정한 방법으로 메모리에 배치되도록 컴파일러에게 지시한다. 이를 통해 프로토콜 데이터와 같은 고정된 형식을 다룰 때 필요한 특정한 메모리 레이아웃을 강제할 수 있다. 프로토콜 데이터와 같은 정해진 형식과 직접적으로 매핑해야 할 때 유용하다.
( 구조체 필드 정렬 문제: 일반적으로 컴파일러는 구조체 필드의 정렬을 최적화하여 CPU의 성능을 향상시키려고 패딩 바이트를 추가한다. 하지만, 이러한 최적화는 고정된 바이너리 형식(예: 네트워크 패킷의 헤더)을 파싱할 때 문제를 일으킬 수 있다. packed를 사용하면 이러한 문제를 방지할 수 있다.)
( packed 속성을 사용하지 않고 데이터를 다루기 위해 수동으로 직렬화하는 방법도 있다. 수동 직렬화는 프로그래머가 직접 데이터의 바이트 순서를 조작하여 구조체 데이터를 특정 형식으로 변환하는 방법이다.)
// 수동 직렬화 예시
void serialize_eth_hdr(unsigned char *buf, struct eth_hdr *hdr) {
memcpy(buf, hdr->dmac, 6);
memcpy(buf + 6, hdr->smac, 6);
*(uint16_t *)(buf + 12) = htons(hdr->ethertype); // 네트워크 바이트 순서로 변환
// 이후에 payload 추가
}packed 속성의 사용은 프로토콜 버퍼를 파싱하는 방법, 즉 적절한 프로토콜 구조체로 데이터 버퍼에 대한 타입캐스트로 구현한다.
struct eth_hdr *hdr = (struct eth_hdr *) buf;수신된 ethernet frame을 파싱하고 처리하는 전체 시나리오는 간단하다.
if (tun_read(buf, BUFLEN) < 0) {
print_error("ERR: Read from tun_fd: %s\n", strerror(errno));
}
struct eth_hdr *hdr = init_eth_hdr(buf);
handle_frame(&netdev, hdr);handle_frame 함수는 ethernet header의 ethertype field 를 살펴보고 그 값에 따라 다음 작업을 결정한다.
ARP는 48비트 이더넷 주소(MAC 주소) 를 프로토콜 주소 (예: IPv4) 로 동적으로 매핑하는데 사용된다. 여기서 핵심은 ARP를 사용하면 다양한 L3 프로토콜을 사용할 수 있다는 것이다. IPv4 뿐만 아니라 16비트 프로토콜 주소를 선언하는 CHAOS 와 같은 다른 프로토콜도 가능하다.
일반적인 경우 LAN에서 어떤 서비스의 IP 주소를 알고 있지만 실제 통신을 설정하려면 하드웨어 주소(MAC)도 알아야한다. 따라서 ARP는 네트워크에 브로드캐스트하고 쿼리하여 IP 주소의 소유자에게 하드웨어 주소를 보고하도록 요청한다.
ARP 패킷의 형식은 상대적으로 간단하다.
+--------+--------+--------+--------+
| HT | PT |
+--------+--------+--------+--------+
| HAL | PAL | OP |
+--------+--------+--------+--------+
| S_HA (bytes 0-3) |
+--------+--------+--------+--------+
| S_HA (bytes 4-5)|S_L32 (bytes 0-1)|
+--------+--------+--------+--------+
|S_L32 (bytes 2-3)|S_NID (bytes 0-1)|
+--------+--------+--------+--------+
| S_NID (bytes 2-5) |
+--------+--------+--------+--------+
|S_NID (bytes 6-7)| T_HA (bytes 0-1)|
+--------+--------+--------+--------+
| T_HA (bytes 3-5) |
+--------+--------+--------+--------+
| T_L32 (bytes 0-3) |
+--------+--------+--------+--------+
| T_NID (bytes 0-3) |
+--------+--------+--------+--------+
| T_NID (bytes 4-7) |
+--------+--------+--------+--------+c로 구현하면 아래와 같다.
struct arp_hdr
{
uint16_t hwtype;
uint16_t protype;
unsigned char hwsize;
unsigned char prosize;
uint16_t opcode;
unsigned char data[];
} __attribute__((packed));ARP 헤더 (arp_hdr)는 링크 계층 유형을 결정하는 2 octet hwtype을 포함한다. 이것은 ethernet의 경우이며 실제값은 0x0001이다.
2 octet의 protype field 는 protocol 유형을 나타낸다. 이 경우 IPv4 로 값 0x0800으로 전달된다.
hwsize, prosize field는 모두 1 octet 크기로 각각 하드웨어 및 프로토콜 필드의 크기를 포함한다.
이 경우 mac 주소 6 byte, ip 주소 4 byte가 된다.
2octet opcode field 는 ARP 메세지의 유형을 선언한다. 이는 ARP Request(1), ARP Response(2), RARP Request(3), RARP Response(4) 일 수 있다.
data field 는 ARP 메세지의 실제 payload 를 포함하며 이 경우 IPv4 의 특정 정보를 포함할 것이다.
struct arp_ipv4
{
unsigned char smac[6];
uint32_t sip;
unsigned char dmac[6];
uint32_t dip;
} __attribute__((packed));smac, dmac은 송신자와 수신자의 6 byte MAC address를 포함하고 sip, dip 는 각각 송신자와 수신자의 IP address를 포함한다.
?Do I have the hardware type in ar$hrd?
Yes: (almost definitely)
[optionally check the hardware length ar$hln]
?Do I speak the protocol in ar$pro?
Yes:
[optionally check the protocol length ar$pln]
Merge_flag := false
If the pair <protocol type, sender protocol address> is
already in my translation table, update the sender
hardware address field of the entry with the new
information in the packet and set Merge_flag to true.
?Am I the target protocol address?
Yes:
If Merge_flag is false, add the triplet <protocol type,
sender protocol address, sender hardware address> to
the translation table.
?Is the opcode ares_op$REQUEST? (NOW look at the opcode!!)
Yes:
Swap hardware and protocol fields, putting the local
hardware and protocol addresses in the sender fields.
Set the ar$op field to ares_op$REPLY
Send the packet to the (new) target hardware address on
the same hardware on which the request was received.변환 테이블은 ARP의 결과를 저장하는데 사용되며 이를 통해 호스트는 캐시에서 해당 항목을 이미 가지고 있는지 확인할 수 있다. 이를 통해 불필요한 ARP 요청으로 네트워크 스팸하는 것을 방지할 수 있다.
알고리즘은 arp.c에 구현되어있다.
마지막으로 ARP 구현의 궁극적인 테스트는 ARP 요청에 올바르게 응답하는지 확인하는 것이다.
$ ./arp_example
ARP CACHE INIT
Found ARP entry for IP: 3232235522
ARP Cache Contents:
State Timeout(s) HW Address IP Address
Resolved 30 06:05:04:03:02:01 192.168.0.2.png)

